Predicting Diabetes: A Data-Driven Approach
Diabetes is a growing health concern worldwide, and early detection is key to managing it effectively. This project set out to predict whether an individual is likely to develop diabetes based on a range of diagnostic measurements. With the help of machine learning, we aimed to create a model that can analyze these medical indicators and make predictions that might one day support healthcare professionals in early diagnosis.
Data Behind the Prediction
The data used in this project comes from the National Institute of Diabetes and Digestive and Kidney Diseases. The dataset includes information from Pima Indian women over the age of 21, providing insights into several health metrics. Each entry contains parameters like:
- Number of pregnancies
- Glucose levels
- Blood pressure
- Skin thickness
- Insulin levels
- BMI (Body Mass Index)
- Diabetes pedigree function (a measure of hereditary diabetes risk)
- Age
With these attributes, we aimed to predict a binary outcome: the presence or absence of diabetes. This dataset, curated for diagnostic purposes, offers a focused view, helping us create a model that could potentially aid in diabetes screening.
The Methods: Random Forest and Logistic Regression
To tackle this binary classification problem, we tested two algorithms: Random Forest and Logistic Regression. Each has its strengths and unique approach to making predictions.
Random Forest
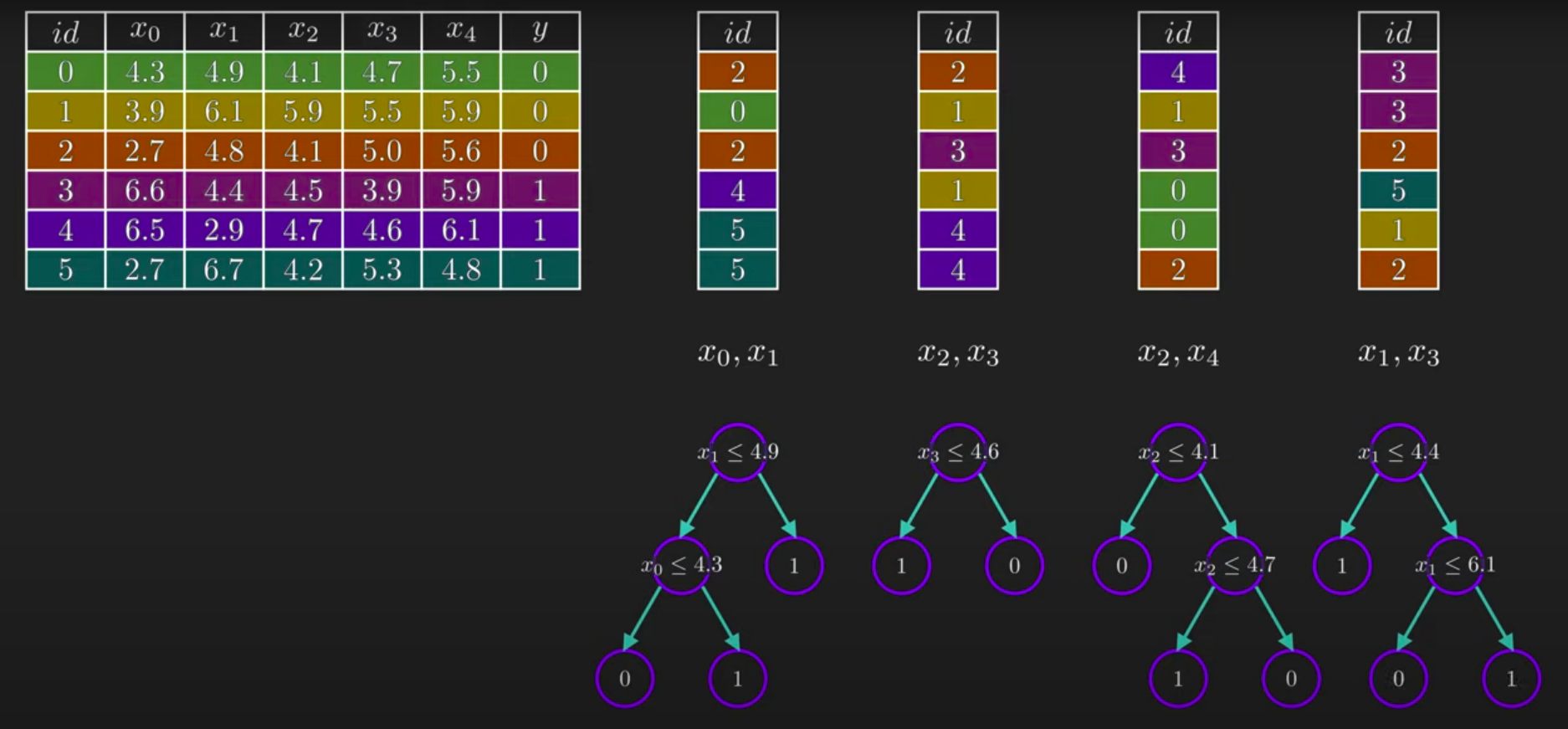
Imagine a forest of decision trees, each trained on slightly different subsets of data. Each tree makes its own prediction, and the forest as a whole combines these predictions for a final decision. By averaging the results (for regression) or taking a majority vote (for classification), Random Forest reduces the chance of overfitting, often delivering robust, accurate predictions. For example, in our project, if 80% of the trees predict diabetes, the forest will classify the individual as likely to develop diabetes.
Logistic Regression
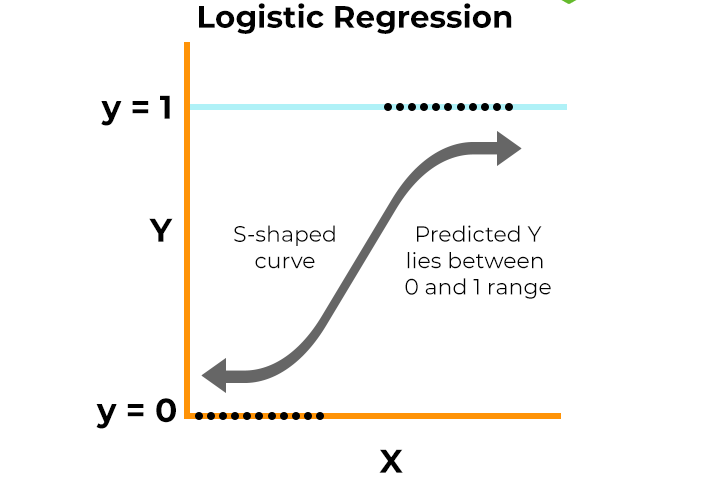
Logistic Regression is simpler yet highly effective for binary classification. Rather than predicting a direct yes or no, it calculates the probability of an individual developing diabetes. Using a sigmoid (or logistic) function, it outputs a value between 0 and 1. If this probability crosses a threshold—typically 0.5—the model predicts "diabetes present"; otherwise, it predicts "no diabetes." Logistic Regression is particularly useful for understanding the impact of each feature on the outcome.
Process and Results: Testing for Robustness
To evaluate the performance of our models, we used a cross-validation approach:
- Each time, we randomly selected 10 data points as a test set, leaving the rest as training data.
- We recorded the accuracy of both algorithms for each test set.
- This process was repeated 10 times to ensure variability, and we averaged the results to get a reliable measure of accuracy.
In our results, both models performed similarly:
- Random Forest achieved an average accuracy that hovered around 75% to 89% across different runs.
- Logistic Regression also performed consistently, with accuracies around 72% to 91%.
- While Logistic Regression slightly outperformed Random Forest on average, the two algorithms demonstrated comparable results, indicating that either could be a viable choice for this problem.
Key Insights and Future Considerations
This analysis highlights the feasibility of using simple, accessible data points to make impactful health predictions. Although both models performed well, a few future enhancements could strengthen the predictions:
Additional Data and Features: Incorporating more health parameters or lifestyle factors could provide deeper insights and improve accuracy.
Feature Importance Analysis: Understanding which features (like glucose levels or BMI) have the most impact on the prediction could help in fine-tuning the model and focusing on critical health markers.
Broader Patient Demographics: Extending the dataset to include individuals from various backgrounds would make the model more generalizable and valuable across a broader population.
Conclusion
By combining patient data and machine learning, this project offers a glimpse into how predictive modeling can support medical decisions. Though not a substitute for professional diagnosis, a model like this could serve as an early screening tool, potentially catching diabetes in its early stages and enabling timely intervention.